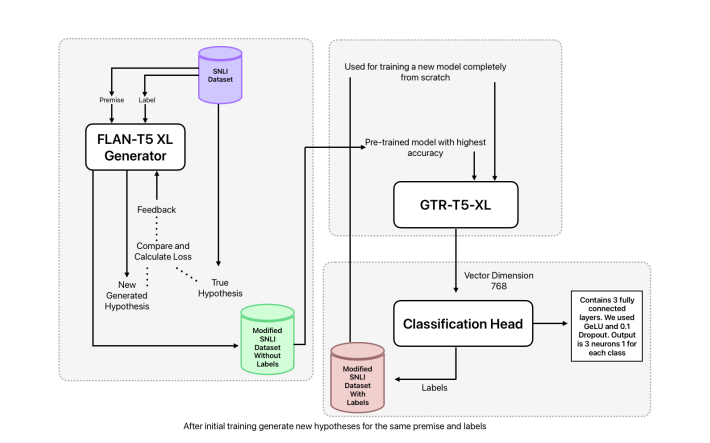
First Train to Generate, then Generate to Train: UnitedSynT5 for Few-Shot NLI
The pursuit of leaderboard rankings in Large Language Models (LLMs) has created a fundamental paradox: models excel at standardized tests while failing to demonstrate genuine language understanding and adaptability